
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Normaltic
- Private AI
- NLP
- kali
- pynput
- youtubeNormaltic
- MachineCode
- CProgramming
- 노말틱
- NLTK
- 모두의 깃&깃허브
- DNS해킹
- bagofwords
- lemmatization
- 딥러닝
- 15679
- bettercap
- c언어
- pos tagging
- 해킹입문
- 비트시프트
- C
- CodeTranslation
- DNS개념
- stopword
- AI
- MITM
- 동형암호
- 해킹 용어
- HEaaN
- Today
- Total
일단 테크블로그😊
[AI/NLP] Bag of Words(CountVectorizer) vs TF-IDF 본문
0. 접근
자연어를 처리하는 방법에 대해 조금 더 생각해 보자. 이전 NLTK 포스팅(NLTK를 통한 자연어 처리 기초개념(Tokenization, Stopwords, POS tagging, NER, Stemming, Lemmatization)에서 자연어를 어떤 식으로 가공하는지 까지는 이해하였다. Token 단위로 자연어를 자르고, Stopwords들을 제거하고, Stemming이나 lemmetization을 통하여 단어를 표준화시키기는 하였지만, 이렇게 처리한 자연어는 아직 자연어이다. 즉, 숫자만 알아듣는 컴퓨터에게 이 가공된 자연어를 컴퓨터에 어떻게 변환시켜 이해시킬 것인가? 에 대한 근본적인 해답은 없는 상태이다.
[AI/NLP] NLTK를 통한 자연어 처리 기초개념(Tokenization,Stopwords,POS tagging,NER,Stemming,Lemmatization)
0. NLTK란? NLTK는 자연어 처리를 위한 대표적인 파이썬 라이브러리이며, 자연어 처리 분야에서 학계와 산업 현장을 가리지 않고 널리 사용되는 인기 있는 툴킷이다. NLTK가 제공하는 대표적인
ben8169.tistory.com
그러면 가장 간단하면서도 일차적으로 생각해 볼 만한 방법은 무엇인가? 바로 단어의 빈도수를 기반으로 자연어를 숫자(정확히 말하면 고정된 길이의 벡터)로 변환하는 것이다. 신문기사를 예로 들면, 인공지능에 대한 기사는 인공지능과 관련된 단어가 많이 등장할 것이 일반적이고, 축구 기사에서는 축구 관련된 용어가 많이 등장할 것이 당연하다. 이와 같이 '단어의 등장 빈도수는 주어진 text의 특징을 잘 나타낼 것이다'는 가설은 꽤 합리적이므로, 이를 기반으로 텍스트 데이터를 벡터로 변환하여 머신러닝 모델에 사용해 보려는 시도가 있었고, 이 과정에서 등장한 대표적인 기법이 CountVectorizer와 TF-IDF 기법이다.
1. CountVectorizer를 통해 만든 Bag Of Words(BoW)
CountVectorizer는 scikit-learn 클래스로써 주어진 텍스트 문서의 단어나 토큰 개수를 세어 행렬로 변환해 주는 역할을 한다. 해당 클래스의 파라미터를 통해 Stopwords를 제거하거나, word count threshhold의 최대 최소를 지정하거나, 단어 개수 제한, n-gram 생성 등을 할 수 있다.
#CountVectorizer 호출
from sklearn.feature_extraction.text import CountVectorizer
#==========인스턴스 생성 및 파라미터 수정==========#
vectorizer = CountVectorizer()
## 불용어 제거
vectorizer = CountVectorizer(stop_words='english')
## Maximum, minimum count threshold. 설정한 비율에 따라 너무 많이 등장하거나 너무 적게 등장하는 단어를 제거
vectorizer = CountVectorizer(max_df=0.80, min_df=0.20)
## 또는 최대 feature 개수를 정해줄 수도 있음.
vectorizer = CountVectorizer(max_features = 50)
#Default: Unigram(1-gram)이나, 임의로 변경 가능
vectorizer = CountVectorizer(ngram_range = (2, 2))
#===========================================#
#fit_transform을 통해 임베딩
matrix = vectorizer.fit_transform(/d/a/t/a/./t/e/x/t/)
#Feature명 출력
vectorizer.get_feature_names_out()
이렇게 CountVectorizer를 이용하여, 단어의 순서가 중요하지 않은 문서에 대해, 각 단어의 등장 빈도수를 표현한 것이 Bag of Words(BoW)이다. 단순하지만 잘 작동할 때가 있다. 그러나, 단순한 만큼 단어의 실제 의미나 타 단어와의 유사도 등 '언어적 정보'를 제공할 수 없다. 단순히 단어 수를 count 하기만 했기 때문이다.
2.TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF는 단어의 빈도수에 더해 얼마나 그 단어가 중요한지를 나타내는 수치적 표현까지 제공한다. 개념에 들어가기 앞서, TF-IDF는 여러 문서가 있음을 가정하고, 각 문서에 대해 특정 단어들의 빈도수를 세거나, 해당 단어가 나온 문서의 수를 세게 됨을 인지하자. 다음은 문서 3개를 예시로 하여, 각 문서별로 예시 토큰 {감자, 밥, 먹고, 좋아요}가 각각 몇 번 등장했는지 Count 한 수를 기록한 테이블이다. (이러한 Document-Term Matrix를 줄여서 DTM이라 부른다.)
| DTM with TF | 감자 | 밥 | 먹고 | 좋아요 |
| 문서 1 | 5 | 12 | 20 | 18 |
| 문서 2 | 0 | 5 | 6 | 30 |
| 문서 3 | 0 | 0 | 17 | 5 |
TF(Term Frequency)란 말 그대로 용어의 빈도수를 나타내며, 가장 간단하게 구하는 방법은 해당 문서에서 특정 단어의 빈도수를 세는 것이다. 그 외에도 다양한 TF 산출 방식이 존재(불린 빈도, 로그 스케일 빈도, 증가 빈도 등) 하나, 여기서는 단순히 용어의 빈도수를 Count 하는 방식으로 TF를 구한다.
IDF(Inverse Document Frequency)는 DF(문서 빈도수)의 역수를 의미한다. 우선 DF란, 특정 단어가 등장한 문서의 수를 말한다. 예를 들어, {감자}의 경우, 문서 1에서밖에 등장하지 않았으므로 DF는 1이다. {밥}의 경우, 문서 1과 문서 2에서 두 번 등장했으므로 DF는 2이다. {먹고}와 {좋아요}의 경우, 모든 문서에서 발견되었으므로 DF는 3이다. 이와 같이, DF는 해당 단어가 문서 내에서 몇 번 등장했는지, 1번 등장했든 10000번 등장했든 상관없이, 단어가 발견된 문서의 개수를 뜻하게 된다. 이를 바탕으로 DF Table을 그려보면 다음과 같다.
| DF Table | 감자 | 밥 | 먹고 | 좋아요 |
| 1 | 2 | 3 | 3 |
그러나 IDF는 DF의 역수라고 하였지만, 단순히 DF를 총문서의 수 n으로 나누어 역수를 취하지 않는다. 왜냐하면, 단순히 DF/n으로 계산을 할 경우, 총문서의 수 n이 커질수록 IDF의 분자가 된 n값이 너무 커져버리기 때문이다. 따라서 log scale을 취하여 큰 값을 handling 해 주고, 분모에 1을 더해주어 log(n/0) = ∞ 를 방지한다. 따라서, 최종적으로 IDF를 구하는 식은 다음과 같다.

해당 식을 바탕으로 IDF table을 그려 보면 다음과 같다.
| IDF Table (n=3) | 감자 | 밥 | 먹고 | 좋아요 |
| log(3/2) | log(3/3) | log(3/4) | log(3/4) |
이제 TF와 IDF를 전부 구했다. TF-IDF는 TF와 IDF를 곱하기만 하면 된다(TF*IDF). 따라서 최종적인 TF-IDF 테이블은 다음과 같다.
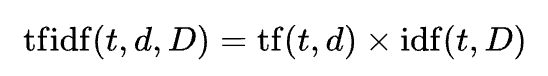
| TF-IDF Table (n=3) | 감자 | 밥 | 먹고 | 좋아요 |
| 문서 1 | 5*log(3/2) | 12*log(3/3) | 20*log(3/4) | 18*log(3/4) |
| 문서 2 | 0*log(3/2) | 5*log(3/3) | 6*log(3/4) | 30*log(3/4) |
| 문서 3 | 0*log(3/2) | 0*log(3/3) | 17*log(3/4) | 5*log(3/4) |
이러한 TF-IDF는 너무 과도하게 등장하거나(abundant) 너무 적게 등장하는(rare) 단어에 낮은 TF-IDF score을 부여하여 penalty를 준다는 점에서 BoW(CountVectorizer) 보다 개선된 방식임을 알 수 있다. 높은 TF-IDF score은 corpus에서 높은 중요도를 가지는 단어임을 나타내는 지표가 된다. 그러나 BoW와 마찬가지로, TF-IDF는 위에 언급했던 단어의 실제 의미나 타 단어와의 유사도 등 '언어적 정보'를 제공할 수 없다는 근본적인 한계가 명확하다. 실질적인 언어적 정보관계를 모델에 학습시키기 위해서는, word2vec이나 Glove와 같은 다른 embedding technique를 사용해야 한다.
🌼세 줄 요약🌼
1. 자연어를 빈도수 기반으로 벡터화하고자 한 BoW(Bag of Words)와 TF-IDF
2. BoW는 문서 내 단어의 등장 빈도수를 집합으로 표현
3. TF-IDF는 단어의 빈도뿐만 아니라 해당 단어가 다른 문서에서 얼마나 많이 등장하는지까지 고려해 단어의 중요성을 측정
😊소중한 의견, 피드백 환영합니다!!😊
'AI > NLP' 카테고리의 다른 글
| [AI/NLP] NLTK를 통한 자연어 처리 기초개념(Tokenization, Stopwords, POS tagging, NER, Stemming, Lemmatization) (0) | 2024.04.25 |
|---|
